What AI Benchmarks Don't Measure About AEC Work
Artificial Intelligence
5
min read

One project runs on a sprawl of knowledge: BIM models, drawings, specifications tied to building codes, contracts, the thousands of emails where decisions get made, review comments, RFIs, and the judgment a senior engineer keeps in their head. That is what your firm knows. Almost none of it sits in a form an AI system can use.
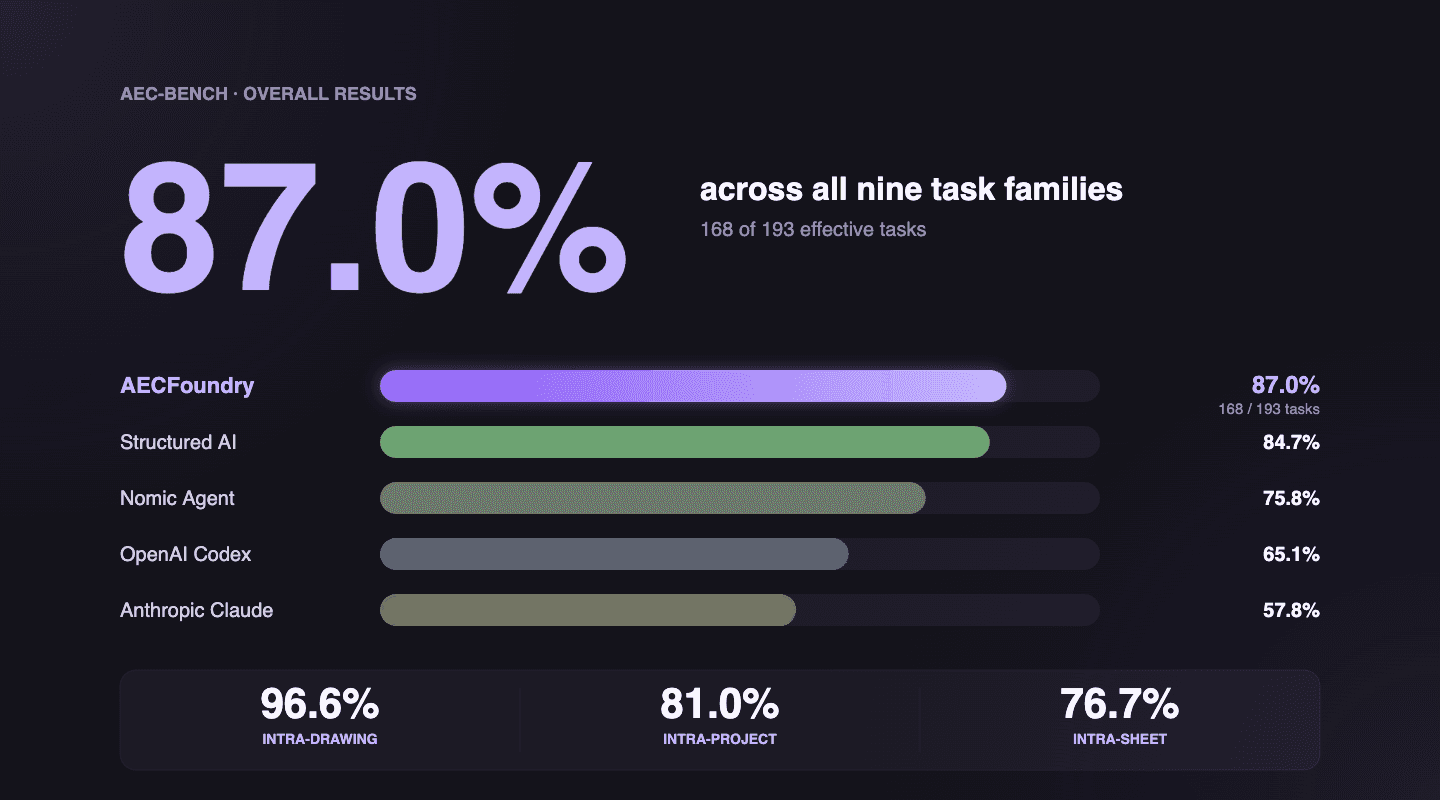
When we published our AEC-Bench results, we showed that the strongest frontier AI agents you can buy today, the best general models with full tooling, still fail on real construction tasks, and that our pipeline beat them by a wide margin. That post settled whether the gap exists. This one looks at what the benchmark left out: how wide the problem runs, and why.
Benchmarks Are Clean. Your Project Data Is Not!
A benchmark is a curated set of well-formed tasks with known answers. The industry needed one, and we are glad it exists. It still looks nothing like your knowledge.
A benchmark also hands you the source. Each task points to the document its answer lives in, which is the only way to mark a response right or wrong. Your projects don't work that way. Nobody tells you which of ten thousand files holds the detail you need, and finding it is most of the job. That distance between a clean task and a messy project is the part the score never sees.
Your knowledge sits across a dozen systems that don't talk to each other, in as many formats. A drawing makes sense only against three other sheets. A spec clause points to a code that governs a detail. A contract obligation lives inside an email thread. A decision survives only because someone transcribed the meeting. The meaning lives in how these pieces connect, and the connections are what no benchmark task captures and no off-the-shelf tool keeps.
A model could ace a public benchmark and still lose its way in your project, because the test never measured what makes the work hard: how scattered and interconnected a firm's knowledge is.
Why Frontier Models Can't Understand Drawing Sets
The reason frontier models stumble on AEC work isn't a mystery, and it won't fix itself with the next release. It comes down to what they learned from.
Large language models learn from the general text of the web and the business world: prose, reports, code, documents read left to right. Vision-language models learn from photographs and ordinary business graphics, such as natural scenes, screenshots, charts, and tables. They are very good at all of it.
A construction drawing is none of those things. It is a symbolic system with its own reading order and layout, where the meaning lives in the cross-references: a callout that points to a detail on another sheet, a door tag that ties a plan to a schedule and back to a spec section. An IFC model is a typed graph of building elements and the relationships between them. A specification is a web of clauses bound to regulations and to details elsewhere in the set. The standard AI toolkit, OCR and vision-language models, flattens all of that into plain text and drops the links that carried the meaning. None of this structure appears in a frontier training set, so the models never learned to follow it.
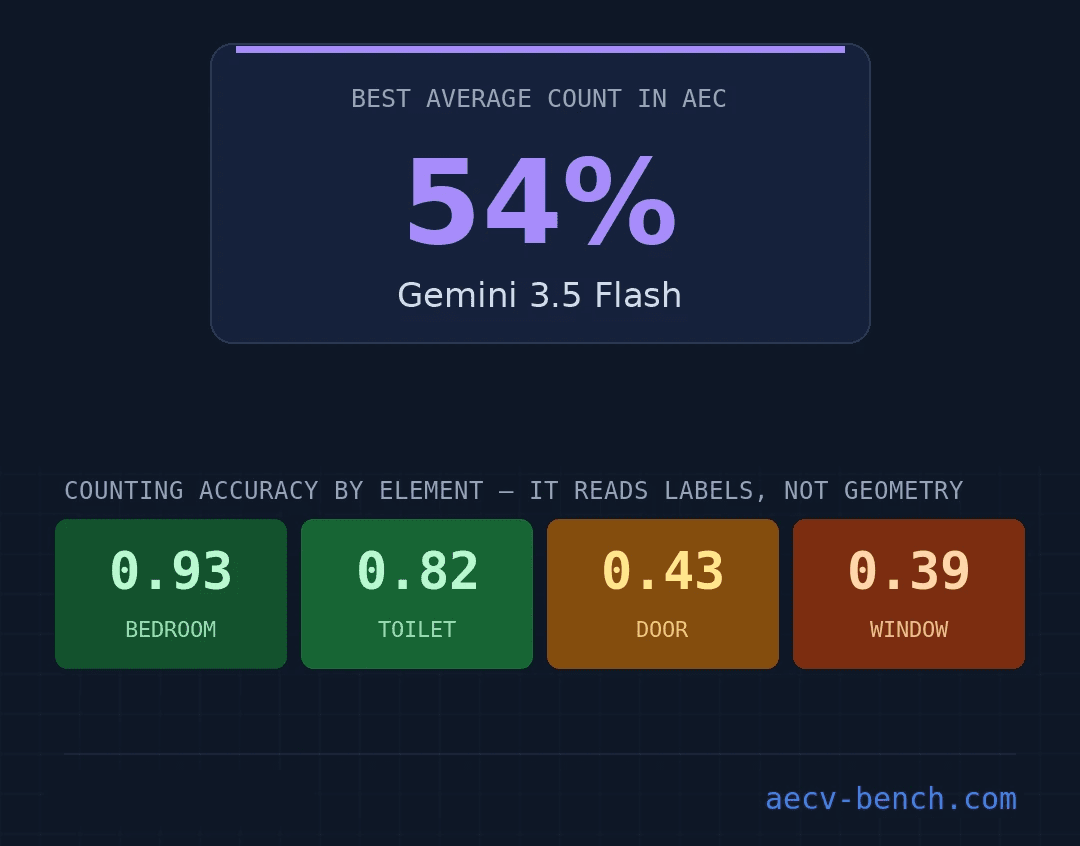
You can watch the failure at its simplest on our own drawings benchmark, AECV-Bench. The best model on the board counts basic floor-plan objects at 54% exact-match accuracy, and it slips to 43% on doors and 39% on windows, symbols a junior drafter reads at a glance. Counting is the easy case: one symbol type, one sheet, no cross-referencing. If a model can't reliably see how many doors sit on a single plan, it has no chance of tracing that door through the schedule, the detail callout, and the spec, which is the work that actually matters. The counting score is the floor, not the point.
So the underperformance is what you would expect. You are asking a system to work with material unlike anything it trained on, in a domain where the structure is the meaning.
You can't prompt your way across a training gap
Waiting for the next model is the wrong plan. A bigger model gets better at what it already knows; it does not wake up fluent in a domain it never saw. The next release will be sharper in general and just as lost in your drawings, your IFC models, and a decade of project decisions.
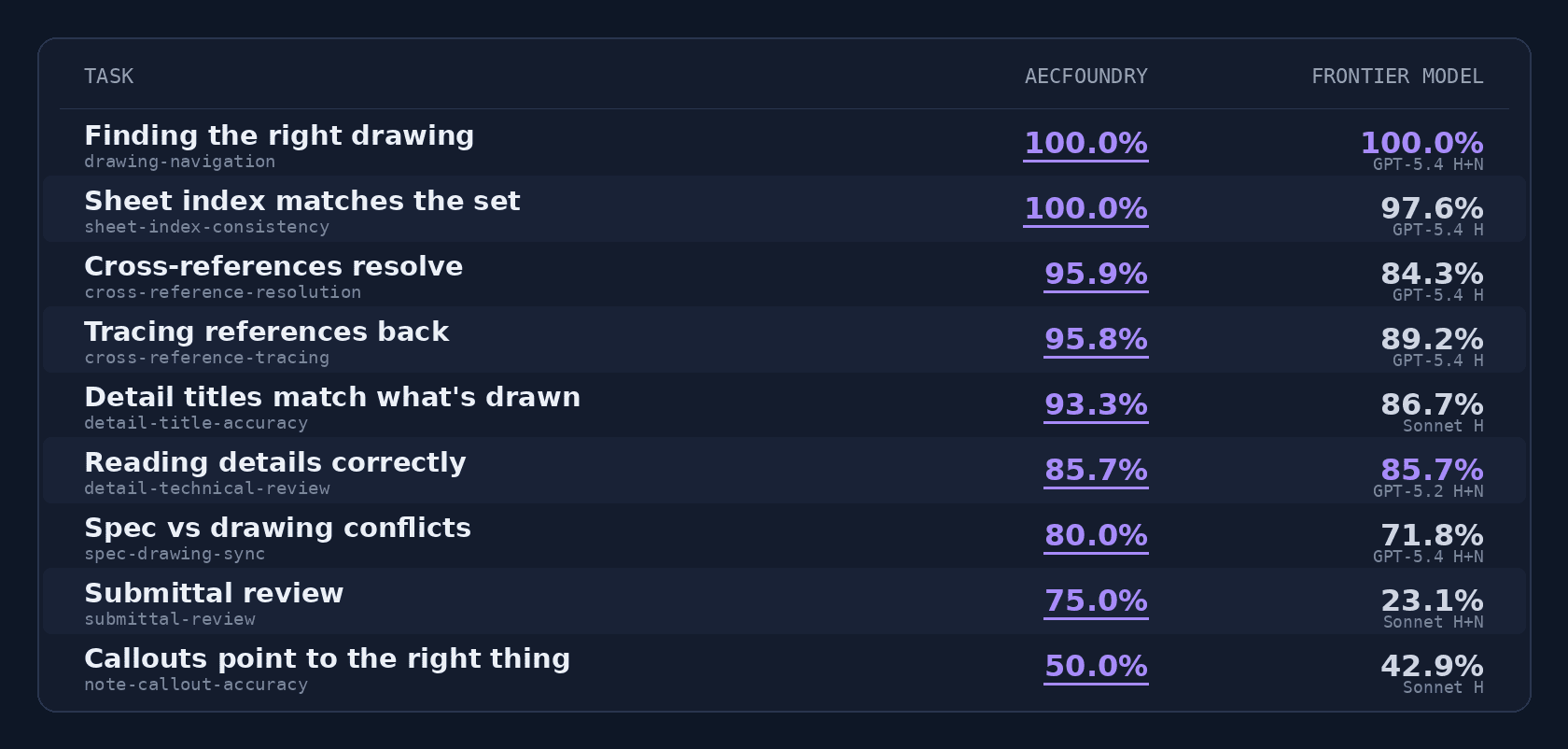
That does not make the models useless. It makes the model the wrong thing to bet on by itself. Put the same model inside a system that hands it structured, connected knowledge and the right scaffolding, and the picture changes. That is how our pipeline beat the general agents on AEC-Bench, Claude Code and Codex among them, by the largest margins on the tasks that demand connecting scattered sources. On submittal review, where you check proposed products against the spec and the drawings, our system scored 75% against 23% for the best general-agent baseline, a 52-point gap. The model carries part of the load. The system gets the job done.
The limit was never the model's raw intelligence. The knowledge your work depends on has never been put in a form the model, or the system around it, can use.
Make Your Data Ready For AI
That points to a more hopeful problem. The job is not to wait for a smarter agent. It is to turn the full range of your AEC-native data, from models and drawings to specs, contracts, emails, and decisions, into one coherent, machine-interpretable layer that keeps its structure and its links instead of flattening them. Do that, and the model becomes the easy, swappable part, while the legible knowledge underneath becomes the advantage that lasts. (The next two posts cover that layer and how it gets built.)
Two things matter from day one. The knowledge has to stay connected, so any finding traces back to the sheet, the clause, or the email it came from. And you can start now, on your own terms, instead of waiting on a release date you don't control.
If you want to see what a coherent knowledge layer looks like across your own models, drawings, specs, and contracts — and which workflows it would let you automate and augment first — that's exactly the conversation we like to start with.