We Topped the First AI Benchmark for AEC Tasks — What We Learned Matters More Than The Score
Artificial Intelligence
7
min read
Two months ago, the first open benchmark for AI on construction documents was published. We ran our pipelines against it. We came out on top.
Document intelligence is the layer of AEC we focus on the most. Turning messy AEC-native data into structured AI-ready knowledge is where we believe the hard work is. AEC-Bench was the perfect opportunity to test our AEC-specific pipelines against a generalized series of tasks and document workflows spanning specifications, construction drawing sets, and submittals. The result lines up with the thesis our work is built around: AI that works on real construction documents lives or dies at the data layer underneath, not at the agent on top.
This is part 1 of a 3 part series of posts where we'll dive deeper into our approach, methodology, tech stack, and lessons learned.
What is AEC-Bench and Why Should You Care
There has never been more software making claims about AI for construction. Most of it is impossible to check. Demos are curated. Slide decks are persuasive. The actual work — running on a real drawing set, against a real specification, with real defects — happens behind closed doors.
A benchmark is how an industry steps out of that. A public test on real documents, scored against ground truth that practitioners agreed on. Anyone can run it. Anyone's claim can be checked.
That matters more now than it ever has. AI in AEC is moving from one-shot prompts to agentic systems: pipelines that read, retrieve, reason, and act across hundreds of pages of project data. The work spans drawings, specifications, submittals, and the relationships between them. A demo that looks impressive on a single sheet can fail completely the moment the work spans a full drawing set. Without a way to measure that gap, every vendor sounds the same.
Nomic published AEC-Bench in April 2026. The benchmark contains 196 real construction tasks across three levels of complexity.

A single drawing sheet — for example, checking that a detail's title matches what is actually drawn, or that a callout points to the right element on the sheet.
A drawing set across multiple sheets — for example, validating that every cross-reference (like "3 / A-201") points to a real sheet and detail, or that the sheet index matches the sheets in the set.
A full project across drawings, specifications, and submittals — for example, finding a conflict between what a specification requires and what a drawing shows, or evaluating whether a contractor's submittal meets the specified requirements.
Each task is graded against ground truth placed by human reviewers. Anyone can run it. Anyone can be measured against it. For the first time, our industry has a shared way to ask whether AI for construction documents actually works.
Why We Ran AEC-Bench, And Why You Should Too
Document intelligence is foundational infrastructure for any domain-specific AI. Before an agent can reason, retrieve, or act, something has to turn raw documents into structured, queryable knowledge — a representation an agent can navigate. Without that layer, agents are guessing. With it, the work becomes tractable.
This is true in every domain. It is especially load-bearing in AEC. The work of designing, building, and operating buildings is mediated by documents — drawings, specifications, submittals, codes, models, contracts. Domain expertise lives inside those documents and inside the practitioners who read them. Any AI that meaningfully helps an AEC firm has to read those documents the way the firm does. That is not a problem you solve at the agent layer.
Three postures exist in this market. Structured AI ships a vertical product — a drawing-review tool built around a fixed library of checks. Nomic ships a platform plus a developer API, sold as a turnkey SaaS deployment. We sit further to the data-first end: a foundational platform — the building blocks of domain-specific AI for AEC — that our forward-deployed engineers configure on each client's knowledge and data, with vertical use cases built and composed on top. Everything is configurable. The work compounds per firm, not from a shared catalogue. This is also exemplified by the products we release as part of our research and business model (SWMS AI, Archie, DocumentFoundry) - all running on the same platform, but released as thin vertical slices to test particular markets and applications.
We benchmark continuously — privately, on client data, against client-defined outcomes — because the discipline of measuring is what tells us whether a deployment is real. AECV-Bench, our open benchmark and paper measuring the performance of multimodal LLMs on construction drawing understanding, was published more than six months ago, and since then a lot of our research has been focussed on turning AEC-native data into AI-ready knowledge.
AEC-Bench (thanks Nomic for the confusing choice in name! ;)) is the first benchmark that attempts to measure the performance of agentic AI on a broader set of tasks representative of everyday workflows AEC professionals are most concerned with. We were curious how our platform, pipelines, and methodology would perform on someone else's yardstick. So we ran it.
The hypothesis we wanted to test is simple. If the knowledge layer underneath is thick enough — extraction, ontology, a graph that represents a project the way a practitioner would — the agent layer on top can be thin and configurable. AEC-Bench is a useful generalized test of that idea, and a perfect testbed for what we're building.
A massive thanks to the Nomic team for creating and releasing this benchmark. This is exactly the kind of data-driven approach to AI that the industry needs.
How We Scored Against the Current Published Field
AEC-Bench groups its 196 tasks into three scopes:
Intra-Sheet — single-sheet understanding. Is the title block consistent? Does this callout match this detail?
Intra-Drawing — multi-sheet reasoning across a drawing set. Cross-references, sheet indices, the relationships between sheets.
Intra-Project — full project reasoning across drawings, specifications, and submittals. The compliance work.

The Headline Numbers
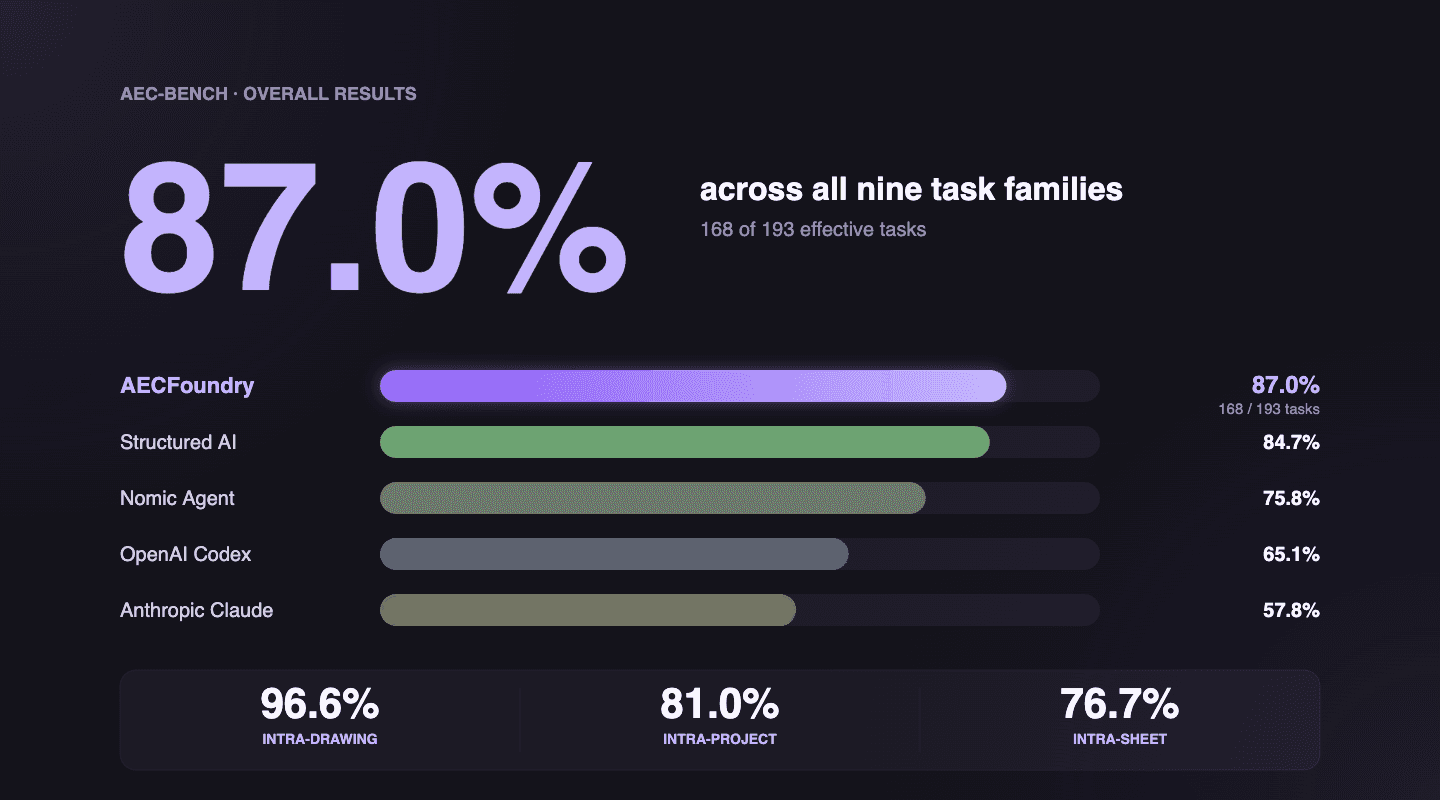
Overall Score: 87%
Multi-sheet drawing reasoning (Intra-Drawing): 96.6%. Three points above the next best published system.
Cross-document coordination (Intra-Project): 81.0%. Within a point and a half of the field leader, ahead of every other configuration the original paper measured.
Single-sheet understanding (Intra-Sheet): 76.7% matching Structured AI with the best published number.
A few numbers in the full table deserve further attention.
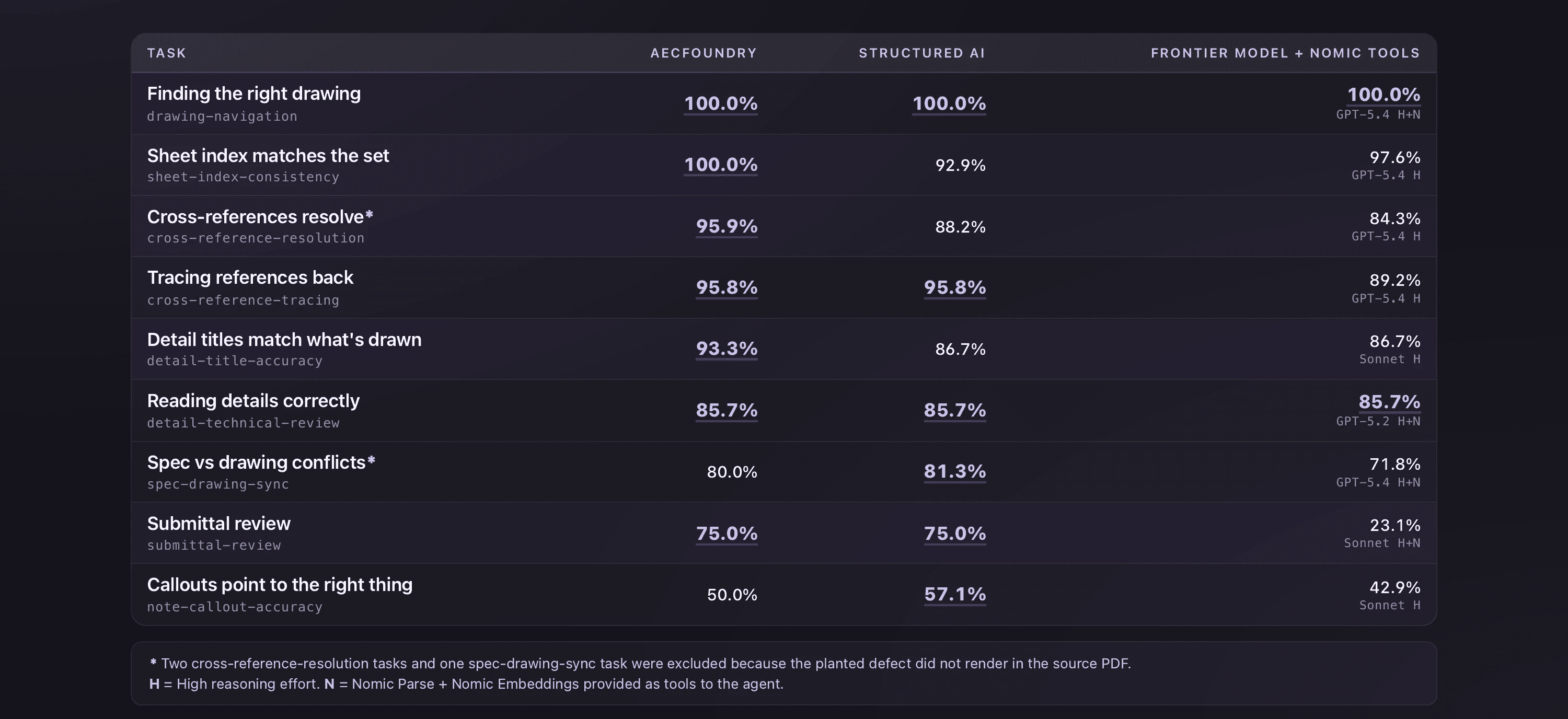
Submittal Review at 75%. A 52-point gap from the closest generic-AI configuration, on the most commercially relevant task family in the benchmark. Submittal review is what slows real projects down. Every product the contractor proposes has to be cross-referenced against the specification, against multiple drawings, and against an implicit understanding of how the project fits together. Generic agents struggle here for one reason: the evidence is scattered across documents, and an agent that cannot find it cannot reason about it.
The multi-sheet drawing scope. Cross-reference resolution 92.1%. Cross-reference tracing 95.8%. Sheet-index consistency 100%. Three task families, all above 92%. Not one strong result. A drawing pipeline that understands a set both semantically and mechanically.
What We Learned
Thick knowledge layer underneath. Thin agent layer on top. That is the architecture under every score in the table above, and it is the choice that separates AI that works on real construction documents from AI that does not.
The Knowledge Layer Is Where The Moat Lives
The common denominator across every document workflow in AEC — code compliance, drawing review, submittal review, RFI response, project research, QA/QC — is the ability to ingest and structure domain-specific data into a unified knowledge layer that AI can access and navigate. Specifications, drawings, BIM models, codes, compliance requirements, submittals, project records. They live in different formats. They participate in the same answers.
Without AI-ready data, there is nothing for AI to work on. That is why our focus has gone heavily into the foundational layers — ingestion, extraction, ontology — and into the graph that holds the relationships between everything a project knows about itself. Specifications linked to drawing entities. Drawing entities linked to submittal products. All bound by a shared vocabulary grounded in MasterFormat, UniClass, OmniClass, and IFC. That graph is what makes multi-sheet and cross-document tasks tractable for an agent of any kind.
It is also why the multi-sheet drawing scope is where the gap on AEC-Bench is widest. The agent layer on top of a knowledge layer like that is comparatively thin — configurable, fast to build, fast to evaluate. AECV-bench gave us a measurement loop on the drawing side before AEC-Bench existed; the same discipline of measuring is what tells us, on each client's documents, whether a deployment is actually working.
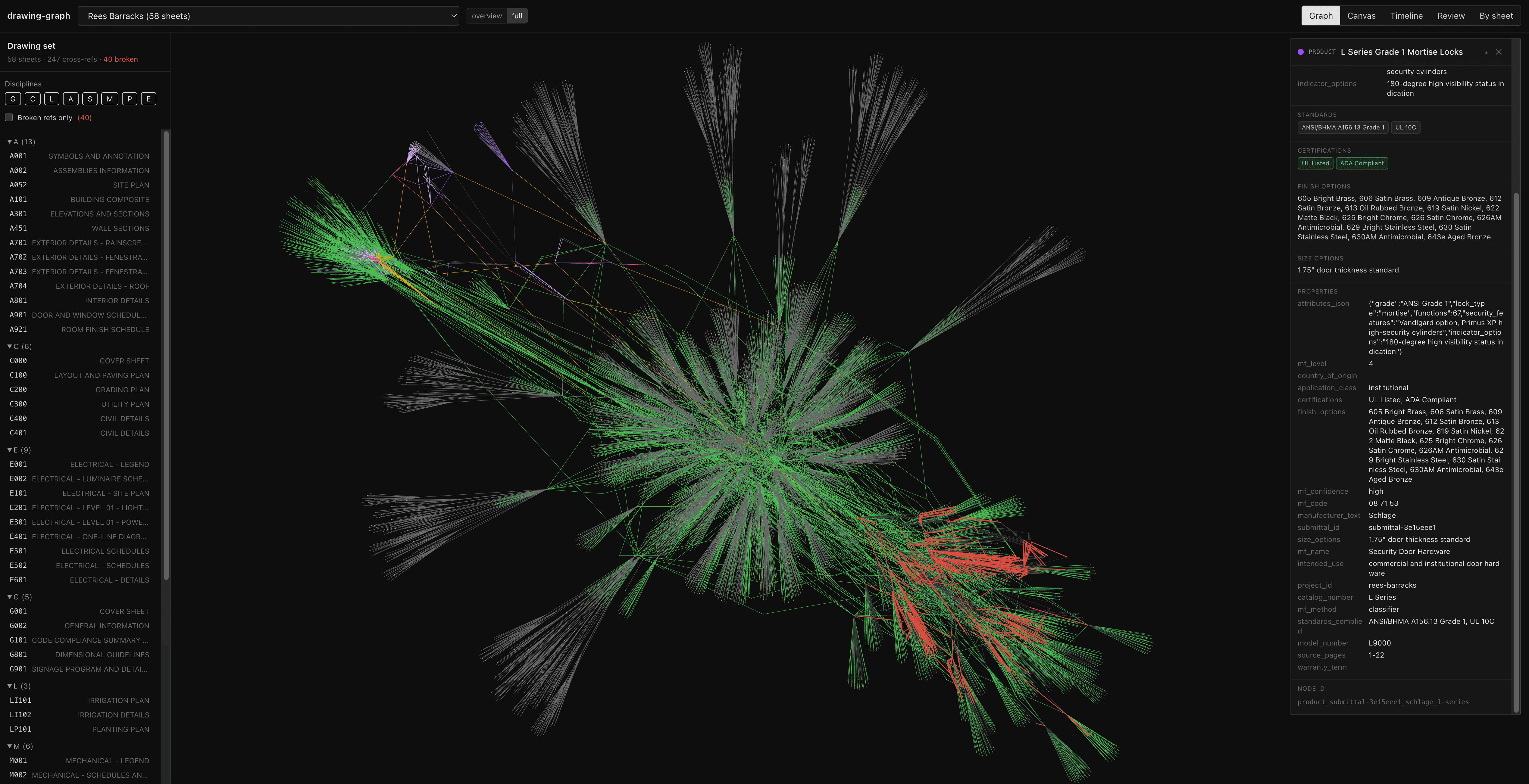
Graph viewer - three interconnected clusters are visible across the project ontology. Submittals in the top left, specifications in the large central cluster, and the drawing set in the bottom right with red edges showing cross-reference relationships.
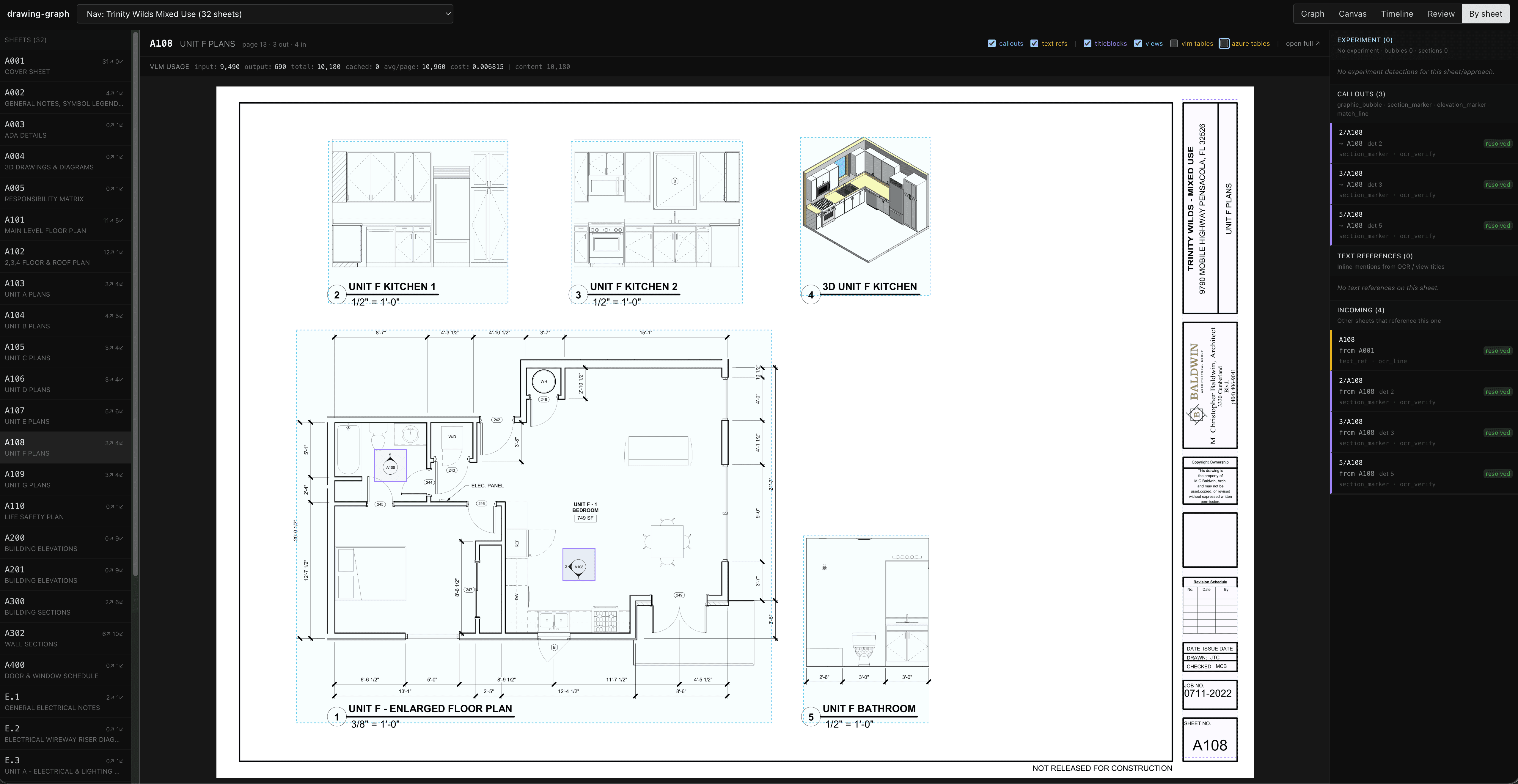
Drawing sheet viewer - displays extracted data including views, callout symbols, tables, title block information, and most importantly cross-references to and from other other sheets.
Compliance Is A Graph Problem
Submittal review is one shape of compliance work. Spec-to-drawing review is another. They share the same structure: requirements on one side, evidence on the other. The work is gathering the relevant evidence and determining whether that evidence satisfies the requirements.
That is the work where generic AI agents and basic RAG pipelines collapse. Not because the underlying models are weak — they are not — but because the evidence is scattered across hundreds of pages and dozens of documents. Simple file tools and keyword search are limited and require many iterations; vector embeddings flatten the structure of the data. A graph that links every requirement to every piece of evidence through a shared vocabulary is what makes the work tractable.
The Three Layers That Matter Most
Three foundational layers hold the rest up.
Ontology — grounded in MasterFormat, UniClass, OmniClass, and IFC, and extensible into each firm's own taxonomies, naming conventions, and proprietary organizational knowledge. The graph only holds together because the shared vocabulary does.
Document intelligence — an ensemble of OCR, custom computer vision models, large language models, vision-language models, and traditional NLP pipelines that ingest, extract, and transform unstructured AEC-native data into structured AI-ready knowledge grounded in the ontology. No single model handles the diversity of a real project documentation set. The pipeline runs several, arbitrates, and resolves to a single source of truth.
Agentic workflows — a dedicated harness composing on top of the knowledge layer rather than around raw documents and generic RAG. Each agent (compliance, drawing review, submittal review, RFI response, QA/QC) navigates the graph intelligently instead of guessing where evidence lives. Configurable per firm, composable across workflows. The agent layer stays thin because the data layer underneath is thick.
Part 3 of this series goes deeper on each. They are worth a separate post.
What The Benchmark Doesn't Measure
A first version of anything has limits. AEC-Bench is the first agentic benchmark our industry has, and it deserves full credit for existing. It also deserves honest treatment.
By design, AEC-Bench evaluates whether an AI finds a specific planted defect in a specific section of a document. It does not evaluate whether the AI surfaces other real issues that nobody planted. A pipeline that does compliance review the way it actually needs to be done — looking holistically at every section, every requirement, every cross-reference — finds more than the benchmark asks for. The benchmark has no way to credit that work.
We saw this in our run. Pre-existing real defects in the source drawings that the benchmark counted as spurious. Ground-truth issues in the benchmark itself. Tasks where the planted defect could not be recovered from the rendered PDF, but our pipeline surfaced the original drawing's real inconsistency anyway.
The benchmark prescribes how to read the documents — and that is the whole game
There is a deeper point in the methodology, and it is the one that matters most for anyone weighing these numbers. AEC-Bench's base configuration gives agents a sandboxed terminal, standard utilities, and PDF rendering and text-extraction tools pre-installed. The published trajectories show what follows. 77% of base runs invoke pdftotext; rasterisation via pdftoppm is close behind. Coding agents converge on the tooling they know, and multimodal construction documents end up treated as flat text. The paper then introduces a second configuration that augments the harness with Nomic's own parsing and embedding tools, Nomic Parse and Nomic Embeddings — the proprietary layer designed to recover the structure that flat extraction throws away. Read carefully, much of the benchmark is not comparing agent architectures at all. It is comparing a pipeline that reads drawings properly against one that does not.
That is our entire thesis, demonstrated from inside someone else's experiment. On real construction documents, the gap between systems lives in the extraction layer, not the agent layer. Submittal Review is the sharpest illustration. It is the most commercially relevant family in the benchmark, and the hardest, because the evidence is scattered across a specification, multiple drawings, and a submittal package that all have to be reconciled. Even the strongest configuration the paper measured — a frontier foundation model equipped with Nomic Parse and Nomic Embeddings — reaches only 23.1. We reach 75.5. That 52-point gap is not about the model, and it is not about reasoning power. Both sides had frontier models running the agent loop. It is about the substrate: a knowledge layer that holds every requirement and every piece of evidence in one graph, so the agent can find what it needs instead of guessing where it lives.
Part 2 of this series will go into the specifics. The short version: a benchmark is a useful starting line, not an end point.
Why This Is Important For AEC Firms
A public benchmark is the start of a conversation. Not the end of one.
The numbers above validate the architecture. They do not validate any specific deployment. What validates a deployment is the same discipline running on your documents — your specifications, your drawings, your submittals, your defects, your project history. Every engagement we run begins with a private benchmark on the client's own data, against the client's own known issues. The evaluation layer is part of the platform because it has to be.
Public benchmarks validate the architecture. Private benchmarks validate the deployment. Both belong to the same discipline.
What AEC-Bench shows is what our platform does without any client-specific configuration. What we deliver in production is more, and the difference has a useful seventy-thirty shape to it.
Roughly seventy percent of the document workflows in an AEC firm look the same across the industry — code compliance, drawing review, submittal review, RFI response, project research, QA/QC. A vertical product can handle that seventy percent. So can a turnkey SaaS platform. That is the segment of the market Nomic, Structured AI, and most of the field are built around.
The remaining thirty percent is where your firm is actually different. Your QA standards. Your project history. Your typical defects. Your design language. Your client mix. Your reasoning behind decisions. The judgement that lives in your senior practitioners' heads. The thirty percent is also where the value of your firm lives — it is what your clients pay you for, and it is what no off-the-shelf product is set up to learn.
Our business model is built around both. We have a platform that delivers the seventy percent on day one — the same foundation that produced the AEC-Bench results above. Our forward-deployed engineers configure and extend it into the thirty percent over the weeks that follow, building vertical use cases on top of that foundation, tailored to your firm, and integrated with your systems. The work compounds as more of your data flows through. The platform improves over time. The thirty percent stays yours.
AI-ready data is the foundation. Ontology is the glue. Scalable intelligence is the value.
Talk to us
The conversations we enjoy most start with the AEC-native data your firm is trying to make sense of or extract value from - drawings, specifications, submittals, BIM, building codes, standards, lessons learned. The expertise sitting in your senior practitioners' heads. We connect it so AI can act on it.
If your firm is serious about turning that data and expertise into machine-interpretable knowledge and executable intelligence — and the demos you have seen so far have not shown much value — we would love to hear what you are working on.
Part 2 — what the benchmark didn't measure — drops next week.



